Introduction
As developers, the first thing we look for when integrating with an external system (or determining whether or not we should) is some sort of documentation. It’s an invaluable tool in increasing efficiency. Given that so many of us rely on documentation, why is it so difficult for us to write it?
Documentation isn’t the most fun part of our jobs, but it’s required for good communication. It’s easy to procrastinate on writing it, however, especially when the reader is internal, because we can always come up with a good excuse: “Documentation is never up-to-date anyway,” or, better yet, “It’s better if they have to come ask me about it.”
The real reason we’re so bad at documentation is that it’s hard to write it in such a way that it’s meaningful for the user, and that it’s difficult to maintain it because constantly tracking changes is tedious and untenable.
Of course, there are some good tools for documentation generation, like javadoc or Doxygen. These tools are great for generating API documentation, but poor with hand-written documentation defining scenarios, examples and best practices. Also, most examples are indeed part of the source code as comments, but they are usually never part of the source code, which makes refactoring ineffective.
What tool should I use?
Let’s step back and examine the core of what we need for documenting our projects and frameworks:
- The ability to share best practices as easily as possible using hand-written examples
- The ability to include snippets to illustrate our examples directly from our source code
This is where a tool like Projbook comes in being:
- An open source project hosted on github
- Released under MIT licence.
- First check in on Sep 26, 2015
- Available from nuget: https://www.nuget.org/packages/Projbook
- Documented here: http://defrancea.github.io/Projbook
- Tweeted about here: @projbooklib
The steps are easy and seamless: Add Projbook using nuget to any of your projects, and it will bring all the default resources you need, like templates (that you can use as-is or customize), default pages as examples (that you will fill out), and default working configurations. Then, when you build your project, it will generate your documentation and drop it into your target directory. The hand-writing part is done in markdown files (called pages) where you can create references to your source code. These references are checked at build time, so if you break a reference, it will not compile, so it guarantees strong documentation-generation checking.
The benefits are:
- You cannot have out-dated documentation because it targets your current build source code
- If you break references, the build will fail, which helps you immediately find the issue
- You can enable PDF generation
- A default, ready-to-go, customizable working template is provided to you from the get-go
I want to use it, but how does it work?
It’s super simple. We’re assuming your project already exists, and your code base is available in front of you.
The first step is going to be adding a documentation project to you solution. Technically, you can reuse any project, but it’s recommended that you have a dedicated project to isolate the effort done in the documentation.
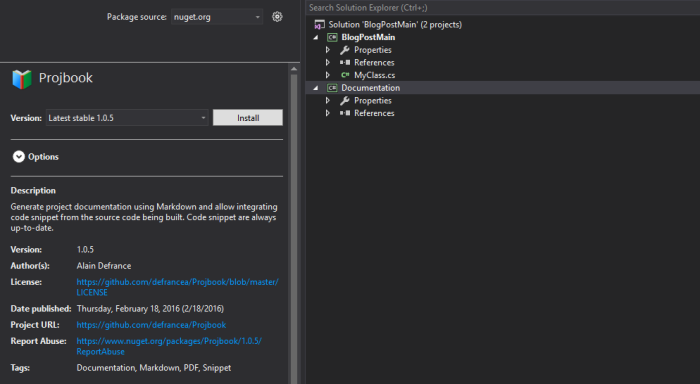
It will automatically set up everything that is required for documentation generation:
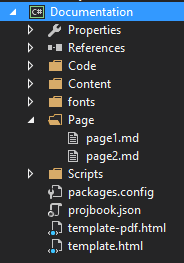
In page1.md, you can see that two snippet references are already set. The first one extracts the full content, and the second extracts the content of the specified member. The following is the example of a method:
Page 1 Whole file content: ```csharp [Code/SampleClass.cs] ``` Just method content: ```csharp [Code/SampleClass.cs] -Method(string) ```
Let’s update it to extract our class content into our existing project:
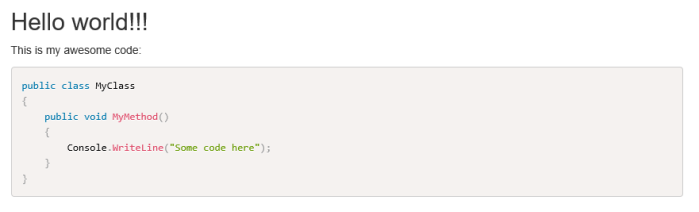
# Hello world!!! This is my awesome code: ```csharp [MyClass.cs] MyClass ```
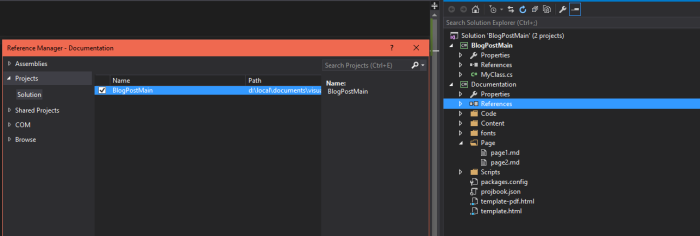
Don’t forget to add a reference from your documentation project to your other project:
Now simply build and you’ll get your documentation in your output directory:
Congratulations, you’re now all set! Refactor your snippet, and the next generation will have the latest version. Break you documentation references, and it will refuse to compile. Think even bigger by making this project run on your build server, and deploy your freshly generated documentation to a public space or internal documentation location. Ask for code reviews during documentation changes and keep track of who updated the content. With Projbook, you can now trust your documentation.
For any requests, please take a look at the current issue list, and give ideas or propose contributions, anything is very welcome.
